Unlocking Data with AI : Transform Documents into Actionable Insights with Azure AI Document Intelligence

Do your PDFs include text as an image? Or are you having trouble extracting your texts with free OCRs because they aren't accurate enough? Don't worry! Azure can solve all of your OCR problems for a small investment!
What is Azure Document Intelligence?
Azure Document Intelligence, previously known as Form Recognizer, is an AI-powered Azure service that employs powerful machine learning algorithms to automatically and precisely extract text, key-value pairs, tables, and structures from PDFs. It also allows you to train the OCR on your own custom-formatted documents to retrieve pertinent information.
Prebuilt vs. Custom extraction Model
Azure includes certain prebuilt OCRs that have already been trained on popular document formats such as invoices, receipts, health insurance cards, and business cards. If your document format is comparable to these, you can use one of the prebuilt models.
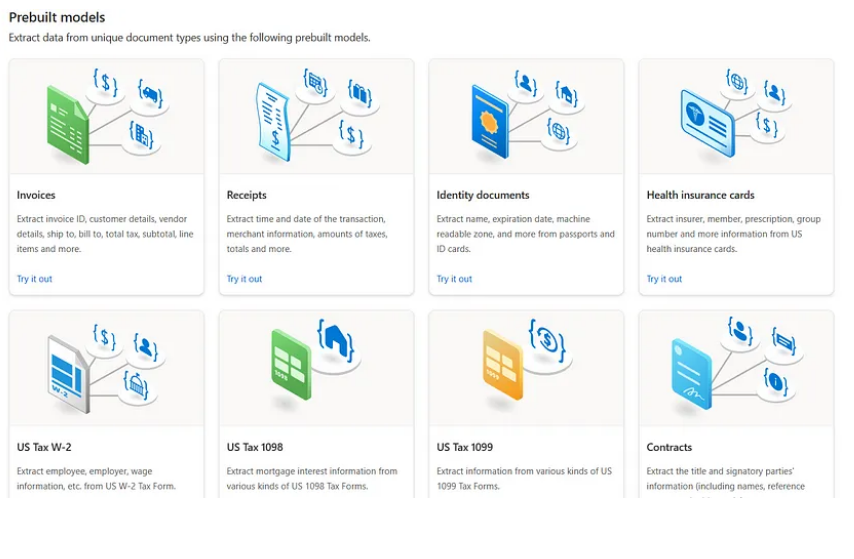
But what if your paper uses a completely different format? Or what if you have several documents in different formats? What if you wish to classify your documents? In this instance, you can create your own OCR, which is a customized extraction model. A unique extraction model gives you an advantage in training the OCR on your custom-formatted data with great precision. You can extract tables, key-value pairs, and selection marks and receive the results in JSON format. Azure also provides code to extract data in Python and C#.
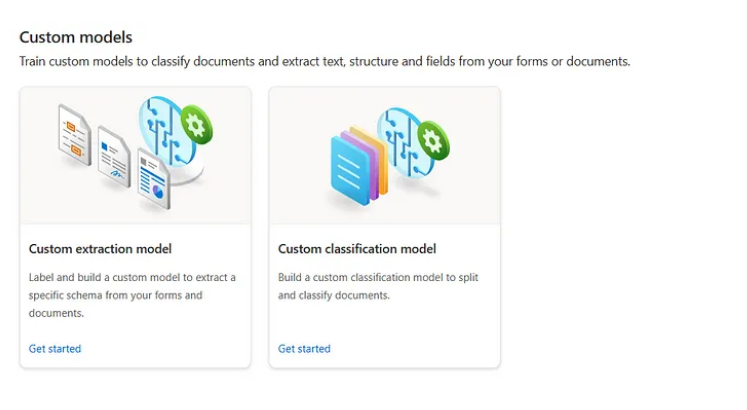
What You Need: Before you begin working with document intelligence
Before you can begin working with Azure, you must first purchase an Azure membership. Also, Azure provides document intelligence for free; however, the free tier only allows you to perform OCR on two pages per document. If you have a huge dataset or work in an organization, you should opt for a "pay as you go" service if you do not know the exact quantity of documents you will need. If you utilize prebuilt models, Azure charges you $10 for every 1000 pages. In the event of a custom extraction model, it charges $50 per 1000 pages. For example, if your PDF comprises 100 pages, it will be counted as 100 pages.
Custom Extraction Model
Most companies that deal with healthcare, legal, or similar data require a custom OCR because of the different document formats. So, Azure gives you an edge to train the OCR on your own custom data. Let’s dive into it!
You must meet certain conditions. To train a solid OCR model, you'll need at least five documents with similar formats. Assume you have a dataset of various retailer companies and you need to process their bills. So, because each organization has a different format, you may train a model for each and then aggregate them together using Azure Document Intelligence's compose option. In this way, your composition model will outperform a single model trained on several formats.
Now, how do you train a model? I'm only posting one document here as an example. To train a model, first submit documents by selecting "Browse for files". Your document is now uploaded. When you click Run Analysis, your entire document will be scanned. Now your document is ready to be labeled.
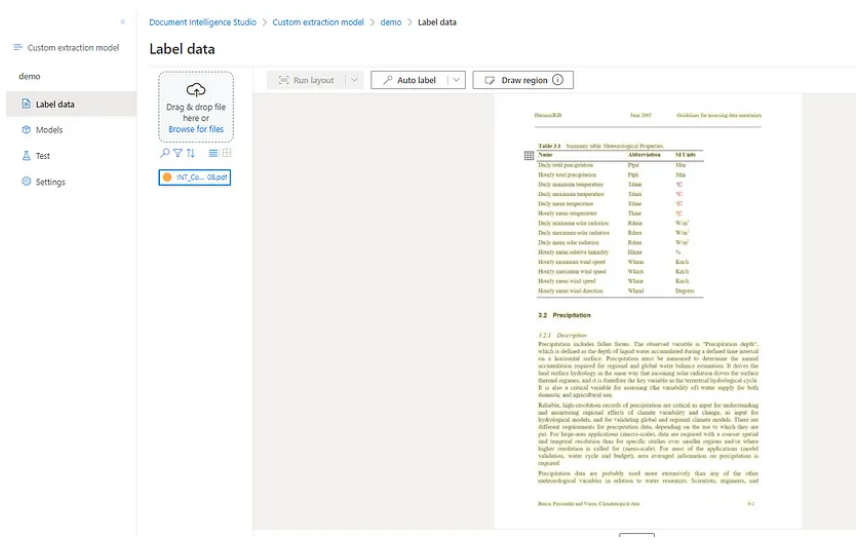
For labelling, you can label or extract key-value pairs, tables, selection marks, signatures, and even the whole page! Wow! Nice, huh?
So, let’s extract the table first. Usually, when you run analysis, it automatically detects tables and auto-labels them for you, as shown below.
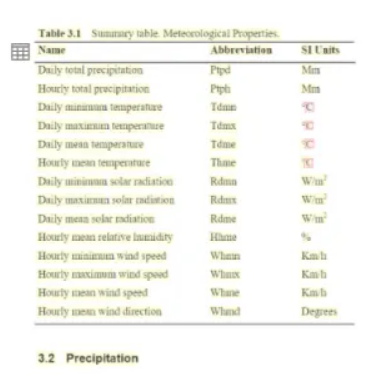
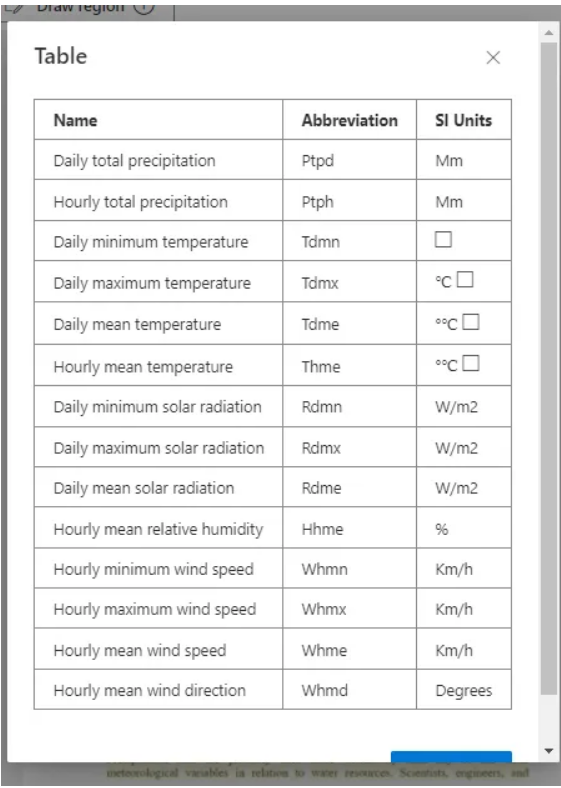
But if you think it is not labeled correctly, you can manually label it. Click on “Add a field” and select "Table.”.
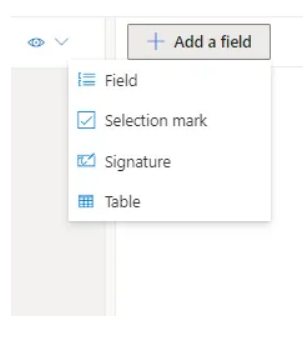
You can create a dynamic table where you won’t need to specify the number of columns and rows and a fixed table with a fixed number of rows and columns.
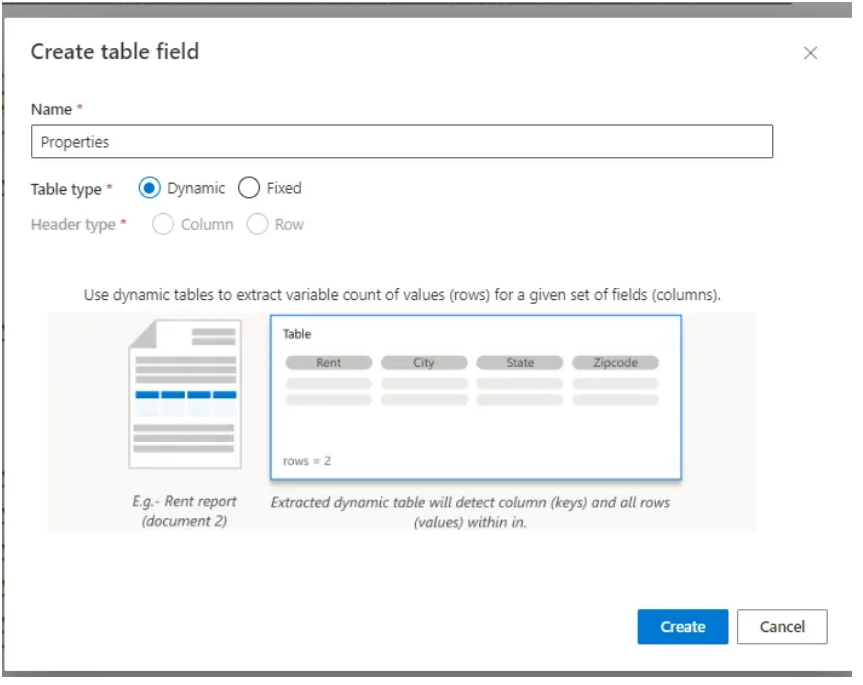
In this tutorial, I'll be developing a dynamic table. So I can now add as many rows and columns as possible. Let's say column one is "Name" and column two is "SI Units". Now the question is, how will I add value to it? Click on words such as daily, total, and precipitation. It will highlight these words in green. Now, click on the first cell of the column name. It will add all of these words to the cell.
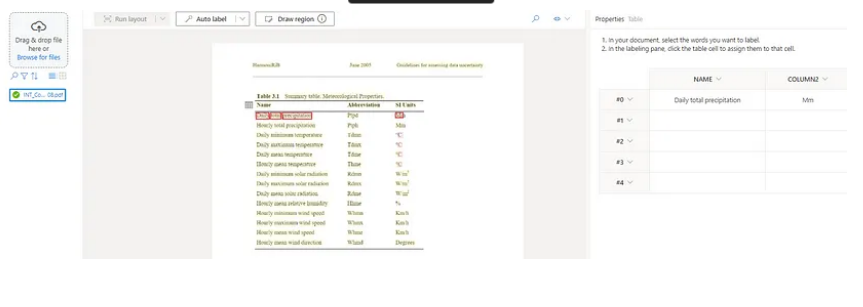
What if there’s a whole page, paragraph, etc. that you want to extract? You can use Draw Region to draw a region based on your specified requirements. Here, I’m drawing a region on the whole page to extract the whole page.
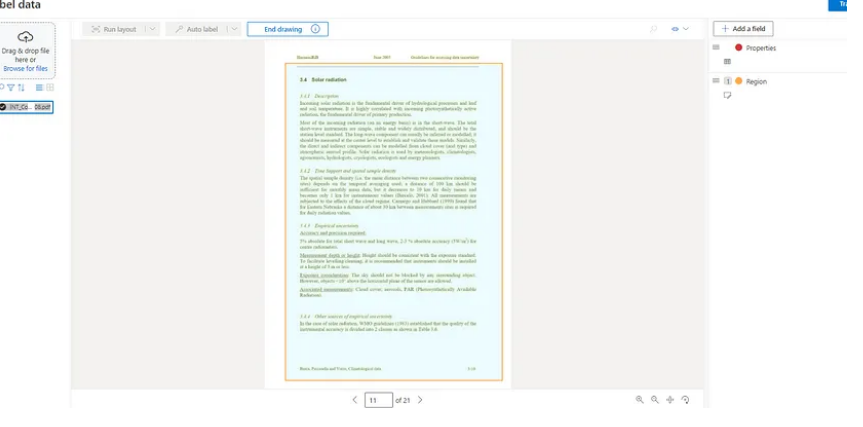
Let’s say you want to extract key value pairs. For example, in this demo, I want to extract equations from each document. So, I’ll create a field equation, label the equation, and assign it to the field equation. You can create as many fields as you want.

Remember to label at least five documents with comparable formats. To train a model, at least five identical documents, such as the one used in this lesson, are required. During the training phase, you may also use prebuilt models as well as your own custom-made models to automatically label documents.
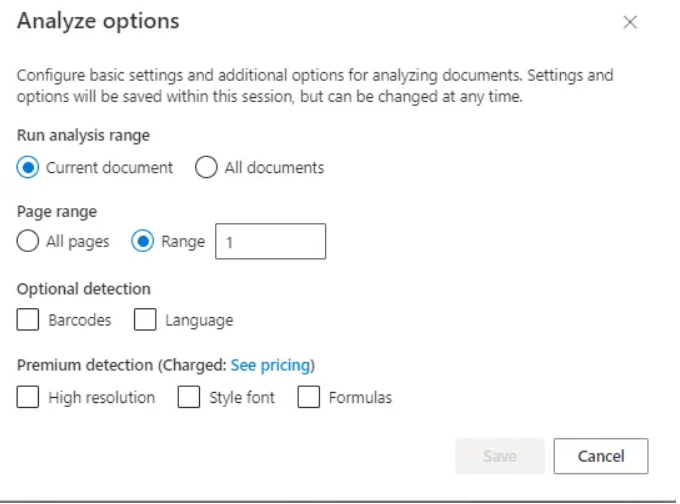
Once you have labeled the documents, click the train button and pick "Neural" as the build mode. You may access all of your models in the model area. Models require time to train, depending on the quantity of documents and pages in each document. Once your model has been trained, navigate to the test page and test it. From the analyze option, you can select some characteristics, such as page range.
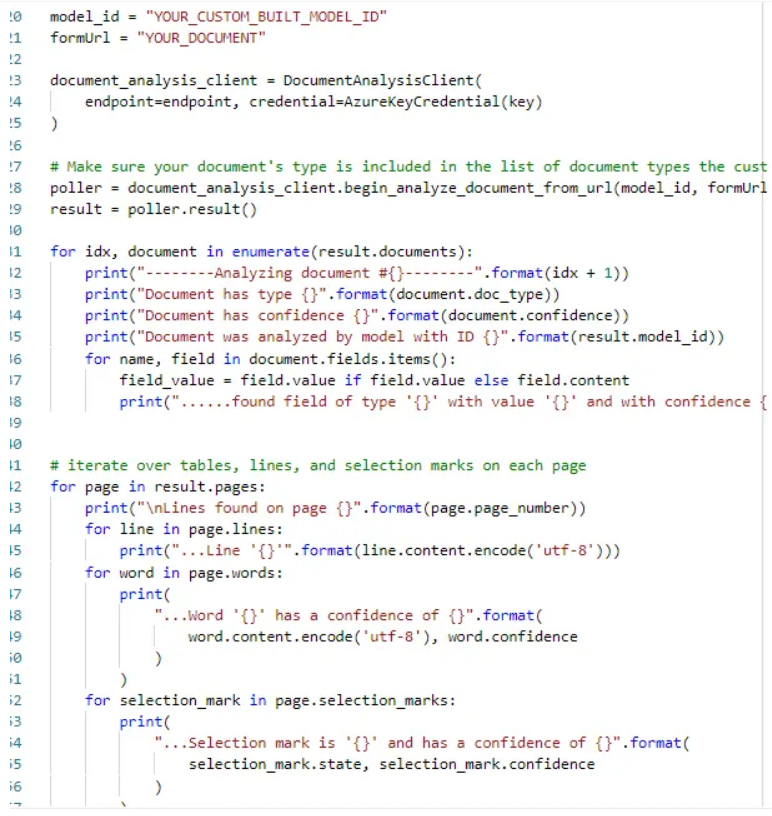
Once you run the analysis, the model will return the results in JSON format, and you can also get generic code in Python, C#, and JavaScript to play with your results.
You can also use this OCR without training any model to extract text using the Python SDK.
Conclusion
Azure's OCR (Optical Character Recognition) is particularly effective at reading text from images and documents. It's like having a highly brilliant friend who can swiftly read and comprehend all types of literature, including difficult ones. What distinguishes Azure's OCR is its accuracy. This implies it makes fewer errors than other OCRs when converting images to text. So, if you've ever been disappointed by previous OCRs' inability to correctly recognize words, Azure's OCR is a breath of fresh air. It's been educated to be extremely intelligent, so it can handle a variety of documents, from simple notes to complex forms. This accuracy allows you to acquire the proper information from your documents, making your task much easier.